

Using the chatbot, ChatGPT, as an example. The “T” in “GPT” stands for transformer, which is an architecture used by a subset of natural language processing (NLP) called large language model, or LLM for short. LLM has become the predominant way to teach computers to read and write like humans do, because it is able to “train” itself on a large corpus of unlabeled text (a word count that is in the trillions) through deep learning and artificial neural network (ANN) technology. To put it in simpler terms, it has taught itself to read and write by parsing the equivalent database of the entire Wikipedia, and so it is able to converse on just about any topic. The part where it draws upon its past training to respond to queries is called “inference”.
So, how does Stable Diffusion or Midjourney or any one of the myriad text-to-image models work? Not so different from ChatGPT, except this time there is a generative image model attached to the language model. These models were also trained on a large body of digital texts and images, so that the AI can convert image to text, (using words to describe what’s in a picture), or vice versa.
Training: How It Works, Which Tools to Use
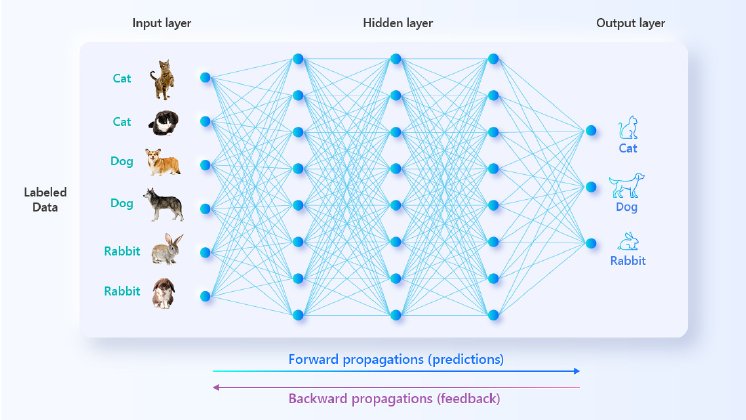
There is a reason why the modern field of machine learning leans heavily into neuroscientific terminology – this branch of AI development benefits greatly from the understanding of the human brain. Humans have billions of neurons in the brains that communicate with each other by forming trillions of synapses. The ANN is also made up of layers and layers of nodes that are modeled on biological neurons; the connections between them are akin to our synapses.
When a piece of datum passes from layer to layer, a weighted score is assigned to the data parameters depending on the validity of the output. Through repeated iterations of predictions (forward propagations) and feedback (backward propagations), the weightings become so precise that the right connections will always be chosen. To employ a rough analogy, one may think of it as the previously analyzed data leaving “grooves” in the algorithm for future data to follow. So, even though the AI doesn’t understand input commands in a literal sense, it has practiced guessing for such a long time on so much data that it can generate an educated response to new input, whether it’s in the form of texts or images.
Earlier methods of training relied on “labeled” data and were supervised by human programmers – which is to say, a lot of hand-holding was necessary. But recent advancements have made it possible for the AI to engage in self-supervised or semi-supervised learning using unlabeled data, greatly expediting the process. The scope of computing resources required to train the AI is not only breathtaking but also ramping up exponentially. For example, GPT-1, which was released in 2018, trained for “one month on 8 GPUs”, using up approximately 0.96 petaflop/s-days (pfs-days) of resources. GPT-3, which was released in 2020, used up 3,630 pfs-days of resources. Numbers are not available for the current iteration of GPT-4, but there’s no doubt that the time and computing involved were greater than GPT-3 by orders of magnitude.
Therefore, for AI training, what is needed is a powerful GPU computing platform. GPUs are preferred because they excel at dealing with a large amount of data through parallel computing. Thanks to parallelization, the aforementioned transformer architecture can process all the sequential data that you feed it all at once. For the discerning AI expert, even the type of cores within the GPU can make a difference, if the aim is to further whittle down the time that it takes to train the AI.
Inference: How It Works, Which Tools to Use
Once the AI has been properly trained and tested, it’s time to move on to the inference phase. The AI is exposed to massive amounts of new data to see if its trained neuron network can achieve a high accuracy for the intended result. In the case of generative AI, this could mean anything from writing a science fiction novel to painting a picture of an ultra-realistic scenery with various artistic elements.

The AI compares the parameters of these new inputs to what it has “learned” during its extensive training process and generates the appropriate output. While these forward and backward propagations are being shunted between the layers, something else interesting is happening. The AI is compiling the responses it receives from the human users for its next training session. It takes note when it is praised for a job well done, and it is especially attentive when the human criticizes its output. This continuous loop of training and inferencing is what’s making artificial intelligence smarter and more lifelike every day.
Computing resources and GPU acceleration are still important when it comes to inferencing, but now with one more consideration: latency. Users demand fast replies from the AI, especially when a lot of the AI-generated content still need to be fine-tuned before they can be of any value. In other scenarios outside of generative AI, a speedy response may affect productivity or even safety, (such as when computer vision is employed to sort through mail or navigate a self-driving mail truck), so it is even more imperative to minimize latency.
The Role of CPU in GPU Computing – with AMD EPYC™ 9004 Sereis “Genoa” Processors
In both the training process and the inferencing process, achieving the lowest latency and the greatest bandwidth of data movement are paramount in performance optimization, in addition to choosing the appropriate GPU model(s). This is statement is true especially when the aspect of data affinity / locality is discussed: having training data as close to the GPU as possible, or processing inferenced data before it is presented to the GPU, requires many fast, high-performance CPU cores. The AMD Genoa CPU processors, in this context, handle essential tasks such as processing of data queries, physical and virtial memory address translation, relational metadata analysis and comparison, data format conversion, encrption and decryption of data over the network, aggregating results computed by GPU and updating models across clusters of nodes, etc.. This is why two flagship GPU server platforms by GIGABYTE / Giga Computing, G593-ZD2 and G293-Z43, are designed with the AMD EPYC™ 9004 Sereis “Genoa” architecture.
G593-ZD2 with Dual AMD Genoa Processors – for Training Workloads
The onboard 8x NVIDIA HGX™ H100 GPU modules are accelerated by two AMD Genoa CPU processors (up to 128 cores per CPU / 256 threads per CPU and up to 400W cTDP per CPU). GIGABYTE was able to fit all this processing prowess into a 5U server thanks to its proprietary cooling tech and chassis design, so that customers can enjoy incredible compute density with a minimal footprint.
G293-Z43 with Dual AMD Genoa Processors – for Inference Workloads
One of the best GIGABYTE solutions for AI inference is the G293-Z43, which houses a highly dense configuration of inference accelerators, with up to sixteen inferencing GPU cards installed in a 2U chassis. The GPU cards are further accelerated by the two AMD Genoa CPU processors onboard, which is optimized for AI inference. The adaptive dataflow architecture allows information to pass between the layers of an AI model without having to rely on external memory. This has the effect of improving performance and energy efficiency while also lowering latency, thanks to the high CPU-core density of the AMD Genoa Series.
It is important to note that AI training and inferencing has been going on long since before generative AI got the market’s attention recently. Clients who develop and deploy AI models often elect to purchase GIGABYTE’s industry-leading G-Series GPU Servers, the E-Series Edge Servers, and R-Series Rack Servers.
Conclusion
Generative AI is finding its way all aspects of the human world, from retail and manufacturing to healthcare and banking. The server solutions depend on which part of the generative AI development process AI experts want to enhance – whether it’s processing data to “train” AI, or the deployment of the AI model so that it can “inference” in the real world. From something as minute as the architecture of processor cores, to something as comprehensive as GIGABYTE Technology’s total solutions, the instruments for achieving success are in place.
























